Recently, I wanted to build a sanitizer for a text input. The text input had rules that excluded come characters. When an invalid character is typed the user should be notified why it does not appear on screen. However, pasting a text from clipboard is also an option so the sanitizer needs to handle multiple invalid characters at once, too.
“Great, there is the CaracterSet API, let’s do this!”
By stating the problem we start by defining a function that has a string as input and needs to produce a sanitized string and the invalid characters that were removed:
func sanitize(input: String) -> (sanitized: String, removed: String?)
Additionally, the set of invalid characters needs to be defined:
let forbiddenCharacters = CharacterSet(charactersIn: "<>.;*")
The input will not be a gigantic string but we want to keep an eye on performance as the function needs to be called on every character the user types. The best we can hope for is a time complexity of O(n), n being the length of the input string.
Let’s start with the most simple approach: filter through the characters of the input string and figure out which characters not belong in there. Those parts need to be memorized in order to tell the user later why the input differs from their expectation. The individual characters need to be concatenated into a single string, which is done in line 9.
func sanitize1(input: String) -> (removed: String?, sanitized: String) {
var removed: String?
let sanitized = input.filter { (character) -> Bool in //O(n)
if forbiddenCharacterSet.contains(character) { //O(1) (Set containment is constant)
// Store the removed character
let forbiddenCharacterAsString = String(character)
removed = (removed ?? "") // Inizializing it only when needed
removed?.append(forbiddenCharacterAsString)
return false
}
return true
}
return (removed, sanitized)
// O(n)
}The time complexity is O(n) since it loops through all the characters and checks if thy are contained in the set. The set containment operation is constant O(1) which gives us the desired complexity of O(n). Yay! 🎉
We even can do better in some scenarios by using set operations! Create a set form the input string and calculate the intersection with the set of forbidden characters. It would be neat if it was possible to get characters out of a character set.
Unfortunately, it is a one way street so there is no way to figure out what characters are contained in the intersection. Another filtering is needed. That might break our performance win as we see.
func sanitize2(input: String) -> (removed: String?, sanitized: String) {
var removed: String?
var sanitized = input
let inputSet = CharacterSet(charactersIn: input) // O(n)
let intersection = inputSet.intersection(forbiddenCharacterSet) // O(min(n,k))
if !intersection.isEmpty {
// Input contains invalid characters, only perform the filter now
sanitized = input.filter { (character) -> Bool in //O(n)
if intersection.contains(character) { //O(1) (Set containment is constant)
...
}
return true
}
}
return (removed, sanitized)
// Filter only performed when needed, but checking for containment is not possible.
// ALSO: Getting characters OUT of a CharacterSet is not possible
// O(n) + O(min(n,k)), when it contains invalid characters, O(min(n,k)) if not
}Time complexity wise, creating a CharacterSet from a string takes approximately O(n) and may be even cheaper. Calculating the intersection of a set is O(min(k, n)) (k being the amount of forbidden characters). In the most cases k is smaller than n.
A CharacterSet is not a normal set so it is unfortunately not possible to create an array from it.
The only way to figure out what elements causes the intersection to be not empty is to filter again. Compared to function #1 it is only done when we have a reason to do so.
Except:
Cannot convert value of type 'String.Element' (aka 'Character') to expected argument type ’Unicode.Scalar'. As it turns out, a CharacterSet is not simply a set of characters Set<Character>! 😖
It is not possible to check if a given character belongs to the
CharacterSet! It is also not possible to retrieve any character out of aCharacterSetor even to convert it back to a string!
Backup strategy:
If CharacterSet does not provide the right APIs for us, we could drop it entirely. We store the forbidden characters in a string let forbiddenCharacters = "<>.;*". Following approach #1 we use the filter function to check if any characters need to be removed form the input. Instead of having the nice constant O(1) lookup operation of a set we need to drop down to a string search operation. That takes O(k) time.
let forbiddenCharacters = "<>.;*"
func sanitize3(input: String) -> (removed: String?, sanitized: String) {
var removed: String?
// Using string containment now.
let sanitized = input.filter { (character) -> Bool in //O(n)
if forbiddenString.contains(character) { // O(k), not a set operation
// Store the removed character
let forbiddenCharacterAsString = String(character)
removed = (removed ?? "") // Inizializing it only when needed
removed?.append(forbiddenCharacterAsString)
return false
}
return true
}
return (removed, sanitized)
// O(k*n) in total
}After filtering we still need to combine the removed characters to a string. Thus, the third approach is O(kn) since for every character in the filter operation the forbidden characters need to be scanned.
But wait, there’s more. We can improve our small algorithm! The String-API gives us one anchor to use our not really beloved CharacterSet: string.rangeOfCharacter(from: CharacterSet). If any character of the CharacterSet is found in the string, its range is returned. However, it only finds the first match. So we need to build a loop to find every occurrence:
func sanitize4(input: String) -> (removed: String?, sanitized: String) {
var removed: String?
var sanitized = input
// Documentation: "This method does not perform any Unicode normalization."
while let range = sanitized.rangeOfCharacter(from: forbiddenCharacterSet) { // O(n)*k
let wrongPart = String(sanitized[range])
removed = (removed ?? "") // Inizializing it only when needed
removed?.append(wrongPart)
sanitized.removeSubrange(range)
}
return (removed, sanitized)
// O(k*n) in total but saves a little because .rangeOfCharacter() will find elements more quickly.
}Apple sadly does not provide any information about the time complexity of this method so we assume that it is O(n). Doing it for every invalid character brings us to O(nk) in total.
That is quite close to our desired O(n). However, it does not produce correct results when unicode is involved. If we waive unicode, we can also modify function #1:
func sanitize1_1(input: String) -> (removed: String?, sanitized: String) {
var removed: String?
let sanitized = input.filter { (character) -> Bool in //O(n)
for scalar in character.unicodeScalars { //O(|unicode scalars in character|)
if forbiddenCharacterSet.contains(scalar) { //O(1) (Set containment is constant)
// Store the removed character
let forbiddenCharacterAsString = String(character)
removed = (removed ?? "") // Inizializing it only when needed
removed?.append(forbiddenCharacterAsString)
return false
}
}
return true
}
return (removed, sanitized)
// O(n) * O(|unicode scalars in character|)
}In the filter function every character’s unicodeScalar is examined and checked if the CharacterSet contains it. The rest is the same logic as before. Time complexity wise an additional loop with O(|unicode scalars of character|) is introduced. Thus giving us the combined complexity of O(n * |unicode scalars of character|).
Wait a minute.
We can not check if a CharacterSet contains a Character but it’s possible to test if it contains a UnicodeScalar! Why isn’t it called “UnicodeScalarSet” then?
🧐
Conclusion
A CharacterSet is really not a set of Characters. We can not check if a string’s character is part of it. It is more a “UnicodeScalarSet”. Since a character can consist of multiple unicode scalars, it is not possible to build a unicode aware API around CharacterSet. It is also impossible to get elements out of a CharacterSet.
If we need unicode support, we'll go with function #3. O(k*n) is quite ok if the invalid characters aren’t too many. Otherwise, function #4 or #1_1 are the best options. With that we come pretty close to O(n).
It wonder why the
CharacterSetAPI is so limited. It even misses the point of its name. Working around its limitations is possible but may be confusing in the first time.
If you want to, you can download the playground here. I would love to hear from you, as well!
Additional information
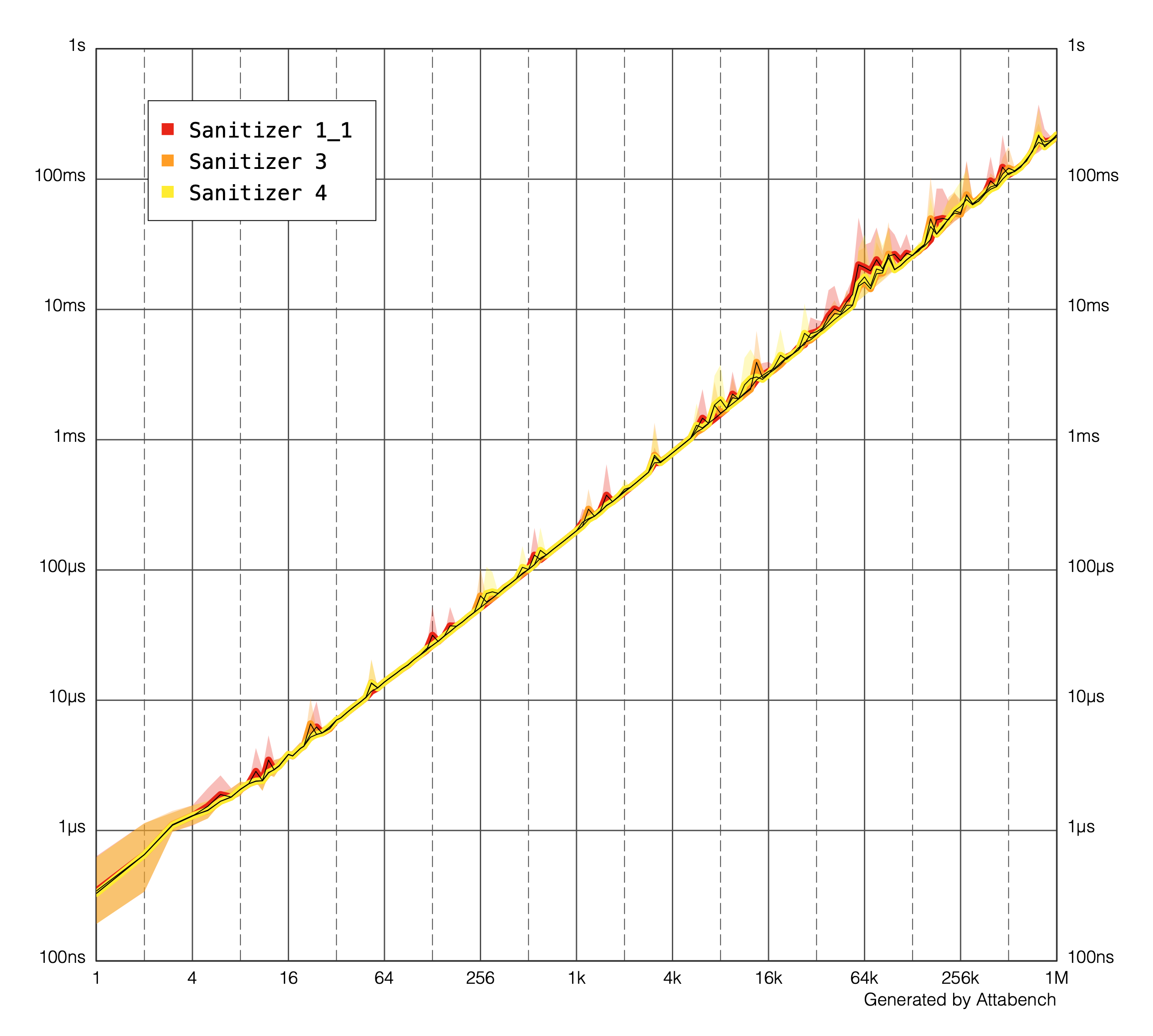
Using Attabench for performance investigations shows that all of the introduced ways are nearly constant and there is no clear winner. However if you need unicode support, function #3 may be the best fit.